
Introduction to Classification Algorithms in Data Mining
Classification Algorithms in Data Mining today became far more critical; it is used to draw out data from a considerable amount of data to assist decision-makers in making good choices. Depending on the kind of type and the data adjustable we would like to predict, we go for the appropriate algorithm. Classification Algorithms in data mining are among the various algorithms in data mining.
Data mining is all about using data analysis tools to discover new, unfamiliar awareness and concealed relationships between the more extensive dataset we’ve on hand. This equipment can manage mathematical algorithms, statistical versions, and machine learning strategies. Classification algorithms in Data mining aren’t simply about collecting and controlling the data though it provides data analysis and prediction.
Here we 1st provide a short introduction regarding the data and classification algorithms in data mining; next, we present classification algorithms in data mining employed in data mining for prediction, and we exist last work as well as experiments with classification algorithms in data mining, like Decision tree, Naive Bayes and logistic regression. The aim is to clearly understand the classification algorithms in data mining and how they’re used in several areas.
What are Classification Algorithms in Data Mining?
The Classification Algorithms in Data Mining is a Supervised Learning method used to determine the group of entirely new observations on the foundation of instruction data. Inside Classification algorithms in data mining, a process learns from the detailed words or dataset and then classifies recent brand mentions into a selection of organizations or classes.

The distinction is recognizing, understanding, grouping objects and thoughts into preset types or “subpopulations.” Using pre-categorized instruction datasets, machine learning plans use various algorithms to classify succeeding datasets into categories. Classification Algorithms in Data Mining learning use input data to predict the probability that consequent data will give away to one of the fixed types. One of the more typical Classification algorithms in data mining applications is filtering email messages into “spam” or “non-spam.”
The distinction is a kind of “pattern recognition,” with classification algorithms in data mining put on the instruction data to search for the same pattern (similar words or sentiments, number sequences, etc.) incoming data sets. Using distinction classification algorithms in data mining, which we will go into much more detail about below, the text analysis program can carry out tasks like aspect-based sentiment analysis to categorize unstructured copy by opposition and subject of opinion (positive, neutral, negative, and beyond).
Try out this pre-trained sentiment classifier to know-how classification algorithms in data mining work in training, then continue reading to learn more about various algorithms.
Types of Classification Algorithms in Data Mining

The study of the classification algorithms in data mining statistics is huge. You can use many kinds of classification algorithms based on the dataset.
Below are Top 5 of the most common algorithms in machine learning.
1. Logistic regression algorithms in data mining:
Logistic regression algorithms in data mining are calculations used to predict binary outcome: something happens or doesn’t. This is displayed as Yes/No, Alive/Dead, Pass/Fail, etc.

Impartial variables are examined to figure out the binary effect, with the results falling into one of two types. The impartial variables might be numeric or categorical; however, the impartial variable is categorical. Written like this:
P(Y=1|X) or even P(Y=0|X) calculates the prospects of reliant adjustable Y, provided impartial adjustable X. This used to compute the possibility of a term getting a negative or positive atmosphere (0, 1, or on a scale) or it is used to figure out the item found in a picture (tree, etc.), grass, flower, with each object provided a probability between 0 and 1.
2. Naive Bayes algorithms in data mining:
Naive Bayes algorithms in data mining calculate the chance of if a datapoint belongs inside a particular category or doesn’t. In-text studies, it used to categorize phrases or words as belonging to a preset “tag” (classification) or not.
For example,
|
TEXT 
“A great game” “The election was a war.” “Immaculate match,” “A clean but forgettable,” “It was a clean election.”
|
TAG Sports Not Sports Sports Sports
Not Sports |
To decide if an adage must be tagged as “sports,” you have to calculate:
P(A/B)= P(B/A) X P(A)
P(B)
OR, if B is correct, the prospects of A is the same as B’s; if A holds, times the probability of A being correct, divided by the possibility of B being actual.
3. K-nearest Neighbors in classification algorithms in data mining
K-nearest neighbors (K-NN) in classification algorithms in data mining is a pattern recognition algorithm that uses instruction datasets to find the k closest relations in succeeding examples.
When K-NN is used in classification algorithms in data mining, you calculate to put details to the group of its nearest neighbor. If k = one, then it will be put into the category to the nearest one. K is classified by a wide variety of forms of its companion.
KNN in classification algorithms in data mining works on the exact process. It organizes the brand new data points based on the category of the vast majority of data points amongst the K neighbor, in which K is the number of neighbors to be looked at. KNN captures the thought of similarity (sometimes called distance, closeness) or proximity with some fundamental mathematical distance formulas, including Euclidean distance, Manhattan distance, etc.
4. Decision Tree
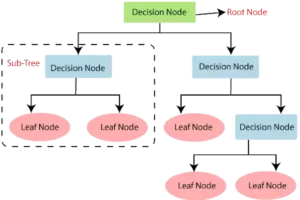
A decision tree is a supervised learning algorithm that’s ideal for classification troubles, as it is in a position to purchase courses on a precise fitness level. It works like a flow chart, sorting out data points into two identical groups at a period from the “tree trunk” to “branches” to “leaves,” the place where the categories are finitely comparable. This produces categories within categories, allowing for organic and natural distinction with limited human supervision.
The Decision tree is just about the most popular machine learning algorithms used. They’re used for both classification algorithms in data mining and regression issues. Decision trees do human-level thinking very easily. It is straightforward to understand the data and make some great intuitions & interpretations. They allow you to see the logic for the data to interpret. Decision trees don’t like black-box algorithms such as SVM, Neural Networks, etcetera.
To proceed with the instance of the sports, that’s the way the decision tree works:
5. Random Forest
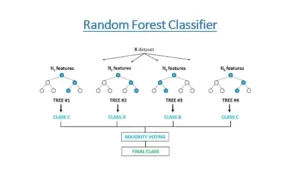
The random forest algorithm in classification algorithms in data mining is an enlargement of a decision tree, in which you initially establish a wide range of decision trees with instruction data, then fit the new data of yours within one of the trees as being a “random forest.”
It averages your data of yours to link it to probably the nearest tree on the datascale. Arbitrary forests are very helpful while treating the decision tree’s situation of “forcing” data points inside a group unnecessarily.
Random forest is an operative machine learning algorithm commonly used in Regression and Classification issues. It creates determination trees on various samples and takes the majority vote of theirs for average and classification in case of regression.
Applications of Classification Algorithms in Data Mining

Now we realize a little of the mathematics powering classification algorithms in data mining, but what can these machine learning algorithms do with real-world details?
- Sentiment Analysis classification algorithms in data mining: Sentiment examination is a machine learning text analysis method that assigns sentiment (emotion), feeling, or opinion to words inside a book, or maybe a whole text, on a polarity scale of Positive, Negative, or Neutral.
- It can instantly go through many pages in minutes or continuously monitor social networking for posts about you. The tweet under, for instance, regarding the messaging app Slack, would be examined to pull all of the person’s statements as Positive. This enables businesses to follow merchandise releases and advertising campaigns in real-time to determine precisely how clients are reacting.
- Email Spam Classification algorithms in data mining: One of the more typical classification applications, working non-stop along with very little demand for human interaction, email spam classification algorithms in data mining saves us from tiresome deletion responsibilities and, at times, expensive spam scams.
Email programs use the above algorithms to compute the probability that contact is possibly not designed for the unwanted or recipient spam. Using text analysis distinction strategies, spam emails are picked out from the regular inbox: maybe a recipient’s name is misspelled, or some scamming keywords are used. Spam classifiers currently have to be taught an amount, as we have all experienced when registering for a contact list that winds up in the spam folder. - Document Classification in classification algorithms in data mining: Document distinction classification algorithms in data mining are the buying of documents into categories based on their articles. It was previously accomplished physically, as in the library sciences, and hand-ordered authorized data. Machine learning distinction algorithms, nonetheless, allow this to be performed immediately.
- Document Classification differs from text classification algorithms in data mining; whole papers are classified instead of just phrases or words. This’s put into practice when working with engines like google online, cross-referencing subjects in legal documents, and searching healthcare data by diagnosis and drug.
- Image Classification in classification algorithms in data mining: Image Classification assigns before skilled groups to a specific picture. These might be the topic of the photograph, a numerical value, a theme, etc. Image Classification may even make use of multi-label picture classifiers, which work similarly to multi-label text classifiers, to tag an image of a stream, for instance, into various product labels, including “stream,” “water,” as well as “outdoors,” etc.
- Using supervised Classification algorithms, you can tag pictures to train your type for suitable varieties. The more you practice it, the better it’ll work like all machine learning versions.
Characteristics of Classification algorithms in Data Mining

Let us discuss the characteristics of classification algorithms in data mining:
- Comprehensiveness: Classification must examine all the things of the data. It must be comprehensive; it classifies all things into a specific team or even category.
- Clarity: There ought to be no confusion about positioning any data product in a team or even category. That’s, classification must be completely clear.
- Homogeneity: The things within a confident team or maybe category must be not unlike one another.
- Suitability: The attribute or characteristic based on which classification is completed should go along with the objective of classification algorithms in data mining.
- Stability: A specific investigation type must be impacted by the same set of classification algorithms in data mining.
- Elastic: As the goal of classification changes, one ought to be in a position to modify the foundation of classification.
Features of Data Mining Algorithms

These are the following main attributes that data mining algorithms generally allow us:
- Automated discovery of patterns.
- Prediction of potential outcomes.
- Development of actionable data.
- Concentrate on big data sets as well as databases.
Advantages of Classification Algorithms in Data Mining

As we now explored, classification algorithms in data mining are the procedure of removing trends and patterns from a lot of data . It’s used to enhance the consumer experience, profitability, and lower chances. Some other advantages of data mining are as follows:
1. Improved performance:-
Multiple models offer better processing power. Greater scalability: As your pc user base expands and article complexity increases, your data of yours can develop. Simplified management of Classification algorithms in data mining simplifies the management of significant or quickly growing methods.
2. It can help identify fraud and risks:–
Classification algorithms in Data mining can help identify changes and fraud that might not be detectable via standard data analysis. It can find different patterns in data that are tough to unrevealed, particularly when the data isn’t organized in a manner that makes it very easy to find out what datatype to search for. One strategy is connection
rule mining, which finds some interactions between dataset variables. This could result in insight regarding the forms of risks present and how to mitigate them down the road.
3. Will help to analyze huge quantities of data swiftly:–
Classification algorithms in Data mining used to analyze data that was, in the past, far too complex to understand because of the complete volume or maybe data type. Furthermore, it’s a crucial part of the contemporary world. Many businesses frequently use it since it can help them make much more informed choices about other business pursuits and advertising.
4. It helps to know behaviors and trends and discover secret patterns –
Classification algorithms in Data mining used to locate trends and patterns in pc user behavior. It lets you do this by searching for anything at all that’s repeated in the data , like instances of shopping for specific products. These classification algorithms in data mining may likewise be used to understand trends, discover hidden patterns, and propose techniques for small businesses.
Disadvantages of Data Mining Algorithms

As explored previously, classification algorithms in data mining are a helpful tool. Nevertheless, it’s not without its drawbacks. The disadvantages of classification in data mining are as follows:
1. Soaring privacy worries:–
One of the leading disadvantages of classification algorithms in data mining algorithms is data and privacy concerns. Traditionally, businesses would share private data along with other companies to be able to do a service.
Nowadays, numerous individuals are concerned that their data is for sale to third parties without their consent. Many people may not feel at ease realizing that the federal government can monitor detailed data about them and how they work with their products.
2. Data mining algorithms call for extensive databases:–
Despite drawbacks, classification algorithms in data mining are among the most effective tools in a marketer’s toolbox. One particular disadvantage is that classification algorithms in data mining call for huge directories to work. For instance, if a contact list has only a hundred individuals, then the data from those emails won’t provide plenty of data for classification algorithms in data mining. On the other hand, if the list has 100,000 persons, there’ll be far more data, and classification algorithms in data mining will be more productive.
3. Costly:–
Classification algorithms in Data mining could be an expensive procedure. For instance, businesses have to employ extra workers and technology specialists to ensure that the data mining is appropriately performed. Numerous organizations need to purchase complex data-mining programs, which are costly. The expense of classification algorithms in data mining outweighs the advantages of them for many little businesses since they do not create good helpful insights.
What are Data Mining Algorithms?

An algorithm of data mining (or machine learning) is a set of analytical plus computations that produce a unit from the data. The algorithm analyzes the data you provide to develop a model, searching for particular kinds of patterns or trends. The algorithm uses the output of this evaluation over a lot of iterations to uncover the ideal parameters for producing the mining version. These parameters are then used throughout the complete dataset to extract actionable patterns and detailed statistics.
What are the Data Mining Algorithms Techniques?
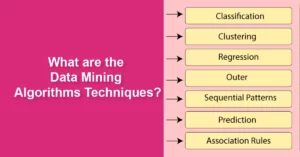
There are many essential data mining techniques to think about when entering the data discipline. Still, several of the most common techniques include clustering, data cleaning, association, data warehousing, machine learning, data visualization, classification, neural networks, and prediction.
- Regression (Predictive)
- Association Rule Discovery (Descriptive)
- Classification (Predictive)
- Clustering (Descriptive)
Top Data Mining Algorithms

Establishing a list of the best data mining algorithms is no simple thing as a result all the algorithms have their distinct objectives and helps in solving specific problems.
Also, you can find several situations in which data mining algorithms are used for obtaining the appropriate answer to a specific problem. As a result, let’s find below the most frequently used data mining algorithms.
1. PageRank:-
PageRank belongs to an URL analysis algorithm designed to determine the presumed value of several objects attached to a network of items. Page Rank (PR) is an algorithm used by Google Search to rank website pages in their search results. It’s named after the phrase “web page” and co-founder Larry Page. PageRank is a method of measuring the benefits of site sites. Based on Google:
- PageRank works by counting the amount and quality of links to a page to figure out a general estimation of just how critical the site’s importance is. The underlying assumption is that many more essential areas will probably get more links from other websites.
- PageRank results from a mathematical algorithm depending on the web graph, developed all Around the world Web pages as hyperlinks and nodes as edges, taking into account authority hubs including mayoclinic.org or cnn.com. The ranking greatly suggests a value of a specific page. A hyperlink to a page counts as a vote of support.
- The PageRank of a page is defined recursively and is determined by the amount and the PageRank metric of all the pages that link to it (“incoming links”). A page that is connected to a lot of pages with a good PageRank gets a higher ranking itself.
- Many academic papers about PageRank have been printed since Page and Brin’s classic piece. In training, the PageRank idea might be susceptible to manipulation. The study has been conducted to identify falsely affected PageRank rankings. The aim is to find a reasonable means of ignoring backlinks from documents with falsely affected PageRank.
2. AdaBoost:-
AdaBoost, short for Adaptive Boosting, is a statistical classification meta-algorithm formulated by Yoav Freund and Robert Schapire, who received the 2003 Gödel Prize for their work. It is used in conjunction with many other learning algorithms to boost performance. The output of the different learning algorithms (‘weak learners’) is mixed into a weighted sum that presents the boosted classifier’s final production.
AdaBoost is adaptive because the following vulnerable learners are tweaked in favor of those situations misclassified by prior classifiers. It could be less prone to overfitting in specific areas than other learning data mining algorithms. The person learners might be vulnerable, but so long as the over
all performance of each one is somewhat much better than random guessing, the final design could be shown to converge to a good learner.
Even though AdaBoost is used by combining inadequate base learners (such as determination stumps), it’s found that it can also successfully blend powerful base learners (such as serious decision trees), producing an even more correct model. AdaBoost is a popular data mining algorithm that sets up a classifier. A classifier is intended to get some data and make an effort to predict which set of new details the component belongs to.
CART data mining algorithms stand for both classifications and regression trees. Essentially, it’s a decision tree learning strategy that outputs either variety or regression trees. Like C 4.5, CART is regarded as a classifier.
3. PCA:-
Principal Components PCA or Analysis is ideal for identifying significant variables in the dataset, becoming a fantastic tool for data evaluation.
The principal parts of a set of points of a genuine coordinate room are a sequence of display style pp system vectors, the place where the display style vector is the path of a series that best suits the data while being coordinated to the very first display style i-1i-1 vectors. At this point, a best-fitting line is described as one which reduces the typical squared distance from the facts to the line.
These instructions comprise a coordinated foundation in which various specific areas of the data are linearly uncorrelated. Principal part analysis (PCA) is the procedure of computing the central pieces and using them to make a difference in the foundation of the data, using just the first couple of principal components and disregarding the rest.
In data analysis, the first principal part of a set of display style pp variables, presumed to be typically distributed, is the derived adjustable created as a linear mixture of the initial variables, which probably describes the most variance. The following principal component represents the most variance in what’s left after the outcome of the very first component is eliminated, and we might move forward by display style pp iterations until all of the variances are explained. PCA is most often used when lots of the variables are highly correlated, and it’s appealing to decrease their number to an impartial set.
4. Collaborative filtering:-
Collaborative filtering for creating suggestion methods is essentially an issue comprising similarity matching. It’s ideal for using advertising stats due to the reality that it offers a product-based recommendation analysis. Collaborative filtering (CF) is a method used by recommender methods. Collaborative filtering has two senses, a narrow one and a far more basic one.
In the more recent, narrower sense, collaborative filtering produces automated predictions (filtering) regarding a user’s interests by collecting tastes or maybe taste data from many people (collaborating). The coordinated filtering strategy’s underlying assumption is that when an individual A has the identical judgment as an individual B on a problem, A is more apt to have B’s opinion on an alternative situation than a randomly selected individual.
For example, a collaborative filtering suggestion process for tastes in tv programming can predict which tv show an end-user must wish to offer a partial list of that user’s preferences (likes or maybe dislikes). Remember that these predictions are particular to the user but use data learned from many users. This differs from the more straightforward procedure of providing an average (non-specific) score for every product of interest, for instance, based on selecting its votes.
5. Bootstrap Aggregating:-
Bootstrap Aggregating is a machine learning data mining algorithm that takes random samples from a dataset while determining the statistic to make the output. Bottom line, you will find a wide range of data mining algorithms offered, while the importance of theirs and consumption link mainly on the outcome you’re attempting to achieve.
Bootstrap aggregating, also called bagging (from bootstrap aggregating), is a machine learning ensemble meta-algorithm designed to enhance the stability and accuracy of machine learning data mining algorithms used in statistical classification and regression. Additionally, it lowers variance and will help to stay away from overfitting. Even though it’s typically put on to choose tree strategies, it is used with any approach.
Also Read : Clustering Algorithms in Data Mining
Related Topics:- Data Scientist vs Data Analyst
Conclusion
Survey on classifications algorithms in data mining (Decision Tree, KNN, Bayesian) and analyzing the moment of the classification algorithms in data mining, we determine that every decision Trees algorithms has a lesser amount of mistake fee. It’s the simpler classification algorithms in data mining as compared to Bayesian and KNN.
The expertise in Decision Tree classification algorithms in data mining is represented in the type of [IF THEN] rules that are easier for humans to understand. The disadvantage of the determination tree classification algorithm in data mining is that it generally involves a specific understanding of statistical encounters to finish the process effectively.
It can additionally be tough to consume variables on the decision tree and exclude duplicate data. As we pointed out, there are lots of specific decision tree algorithms. The CART decision tree algorithm is the most significant algorithm for the distinction of data, Containing the shortest execution time. The outcome of the predictive data mining method on precisely the same dataset demonstrated that the Decision Tree out performs Bayesian classification having the identical accuracy of a decision tree.
Still, other predictive techniques such as KNN, Neural Networks, and Classification algorithms in data mining based on clustering aren’t good results. Up to right here and thanks to our survey, depending on the earlier research, we extract the point that among (Decision tree, KNN, Bayesian) algorithms in data mining, KNN classification algorithms in data mining have lesser accuracy.
Frequently Asked Questions
1. What is the classification algorithm in data mining?
The classification algorithms in data mining that run the distinction are the classifier as the observations are the situations. Classification algorithms in data mining are needed once the variable of interest is qualitative. The distinction technique uses algorithms, including a decision tree, to get helpful data.
2. What is a classification algorithm?
A classification algorithms in data mining is a characteristic that weighs the enter capabilities so that the output separates one class into good values and the other into bad deals. The Classification Algorithms in Data Mining is a Supervised Learning method used to determine the group of entirely new observations on the foundation of instruction data.
Inside Classification algorithms in data mining, a process learns from the detailed words or dataset and then classifies recent brand mentions into a selection of organizations or classes.
3. Which algorithms can be used for classification?
Popular classification algorithms in data mining that can be used for binary classification include:
- Logistic Regression.
- K-Nearest Neighbors.
- Decision Trees.
- Support Vector Machine.
- Naive Bayes.
4. What is classification and types of classification in data mining?
Classification is a data mining performance which assigns things of a set to target classes or categories. The objective of variety is to correctly predict the target category for every situation in the data . For instance, a classification type might be used to recognize loan applicants as low, moderate, or maybe increased credit risks.
Classification algorithms in data mining types are:
- Logistic regression algorithms in data mining:
- Naive Bayes algorithms in data mining:
- K-nearest Neighbors in classification algorithms in data mining
- Decision Tree
- Random forest
5. Is K means a classification algorithm?
K-means is an unsupervised classification algorithm, also known as clusterization, which groups objects into k groups depending on their qualities. K-nearest neighbors (k NN) in classification algorithms in data mining is a pattern recognition algorithm that uses instruction datasets to find the k closest relatives in succeeding examples.
When K-NN is used in classification algorithms in data mining, you calculate to put details to the group of the nearest neighbor of its. If perhaps k = one, then it will be put into the category nearest one.
KNN in classification algorithms in data mining works on the exact process. It classifies the brand new data points based on the category of the vast majority of data points amongst the K neighbor, in which K is the number of neighbors to be looked at.
6. What is KNN classification algorithm?
Summary. The k nearest neighbors (KNN) classification algorithms in data mining is a simple, supervised machine mastering algorithm that is used to resolve both classifications and regression issues. It is not difficult to carry out and understand but has the downside of getting significantly slowed when the dimensions of that data in use expand.
7. Is logistic regression a classification algorithm?
Logistic regression it’s essentially a supervised classification algorithms in data mining. In a distinction issue, the target variable(or output), y, can have just discrete values for a particular set of features(or inputs), X. In contrast to popular thinking, logistic regression Is a regression type.
8. What are the three methods of classification?
Sequence classification methods can be organized into three categories:
(1) feature-based classification transforms a sequence into a feature vector and applies conventional classification methods.
(2) sequence distance-based classification algorithms in data mining.
(3) Email Spam Classification algorithms in data mining: One of the more typical classification applications, working non-stop along with very little demand for human interaction, email spam classification algorithms in data mining saves us from tiresome deletion responsibilities and, at times, expensive phishing scams.
9. Is decision tree a classification?
A decision tree creates classification or perhaps regression types in the type of a tree structure. It breaks down a dataset into smaller and smaller-sized subsets while, at the same time, an associated decision tree is incrementally created. The last outcome is a tree with decision nodes and leaf nodes.
10. Is clustering a classification algorithm?
Data Label: – Classification algorithms in data mining cope with labeled data , whereas clustering algorithms contend with un-labelled details. Stages: – Classification procedure involves two steps – Testing as well as Training. The clustering procedure involves just the grouping of data.








